场景:
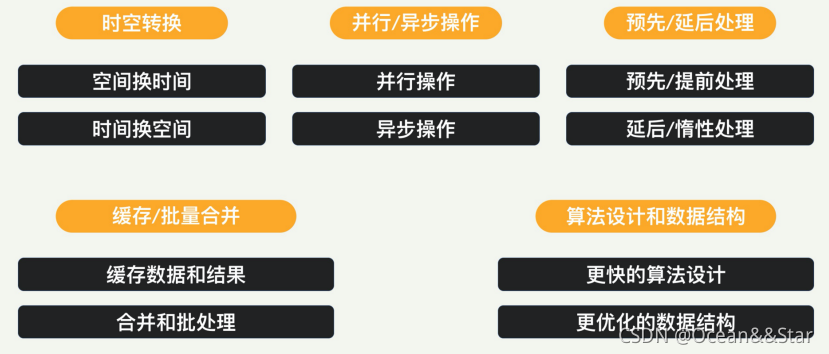
- 一个系统的最大性能瓶颈如果是内存使用量,那么减少内存的使用就是最重要的性能优化。这时可以用时间换空间
- 降低数据的大小以方便网络传输和外部存储:如果系统的瓶颈在网络传输速度或者存储空间大小上,那就尽量采取高压缩比的算法
操作策略:
- 改变应用程序本身的数据结构还在数据格式,减少需要存储的数据的大小
- 想办法压缩存在内存中的数据,比如采用某种压缩算法,真正使用的时候再解压缩
- 把一些内存数据,存放到外部的,更加便宜的存储系统里面,到需要时再取回来
这些节省内存空间的方法,一般都需要付出时间的代价。
关于压缩算法的选取,基本上看三个指标:压缩比例、压缩速度、使用内存
注意,这里的“空间换时间”和后面的缓存策略不同。一般“缓存”使用的空间,和原来的空间不再同一个层次上,添加的缓存往往比原来的空间高出一个档次。而这里的“空间换时间”策略,里面的“空间”是和原来的空间相似的空间。
场景:
- CND内容分发网络:将被访问的数据和服务尽量拷贝到里用户进的地方
- 负载均衡:使用多个服务器(空间)来换取延迟的减少(时间)

场景:
- 网站页面资源的提前加载
- 文本标准规定了至少两种其他加载的方式:preload、prefetch,分别用不同的优先级来加载资源,可以显著的提升页面下载性能。
- 文件系统的预读功能
- 所谓“预读”指的是提前从磁盘读取额外的数据,为下次上层应用程序读数据做准备
- 这个功能对顺序读取非常有效,可以明显的减少磁盘请求的数量,从而提升读数据的性能
- CPU和内存的预取操作
- “预取”是将内存中的指令和数据,提前存放到缓存中,从而加快处理器执行速度
- 缓存预期可以通过硬件或者软件实现,也就是分为硬件预取和软件预取
- 硬件预取是通过处理器中的硬件实现的。该硬件会一直监控正在执行程序中请求的指令或数据,并且根据既定规则,识别下一个程序需要的数据或指令并预取
- 软件预取是在程序编译的过程中,主从插入预取指令(prefetch),这个预取指令可以是我们自己加的代码,也可以是编译器自己加的。这样在执行过程中,在指定位置就会进行预取的操作
所谓“惰性处理”,就是尽量将操作推迟到必须执行的时刻,这样很可能避免多余的操作,甚至根本不用操作。
场景: COW(Copy On Write,写时复制):
- 假如多个线程都想操作一份数据,一般情况下,每个线程可以自己拷贝一份,放到自己的空间里面。但是拷贝的操作很费时间。
- 系统如果采用惰性处理,就会将拷贝的操作推迟。
- 如果多个线程对这份操作只有读的请求,那么同一个数据资源是可以共享的,因为“读”操作不会改变这份数据
- 当某个线程需要修改这一数据(写操作),系统就将资源拷贝一份给该线程使用,允许改写,这样就不会影响到其他线程。
COW应用例子:
- Unix系统fork操作:fork调用产生的子进程共享父进程的地址空间,只有到某个子线程需要进行写操作时才会拷贝一份
- 高级语言的类和容器:比如C++里STL中的string类
异步和并行操作虽然看起来很不一样,其实有异曲同工之妙,就是都把一条流水线和处理过程分成了几条,不管是物理上分还是逻辑上分
并行是一种物理上把一条流水线分成好几条的策略。
-
直观上说,一个人干不完的活,那就多找几个人来干。并行操作即增加了系统的吞吐量,又减少了用户的平均时间。比如现代的CPU都有很多核,每个核上都可以独立的运行线程,这就是并行操作。
-
并行操作需要我们的程序有扩展性,不能扩展的程序,就无法进行并行处理。这里的并行概念有不同的粒度,比如服务器粒度(所谓的横向扩展)。还是在多线程的粒度,甚至是在指令级别的粒度。
-
绝大多数互联网的服务,要么使用多进程,要么使用多线程来处理用户的请求,以充分利用多核CPU。另一只能够情况是在有IO阻塞的地方,也是非常适合使用多线程并行操作的,因为这种情况CPU基本是空闲状态,多线程可以让CPU多干点活。
异步操作是一种逻辑上把一条流水线分成几条的策略。
- 同步和异步的区别在于一个函数调用之后,是否直接返回结果。如果函数挂起,直到获取结果才返回,这就是同步;如果函数马上返回,等数据到达后在通知函数,那么这就是异步。
- Unix 下的文件操作,是有 block 和 non-block 的方式的,有些系统调用也是block 式的,如:Socket 下的 select 等。如果我们的程序一直是同步操作,那么就会非常影响性能。采用异步操作的话,虽然稍微增加一点程序的复杂度,但会让性能的吞吐率有很大提升。
缓存的本质是加速访问。这是一个用得非常普遍的策略,几乎体现在计算机系统里面每一个模块和领域,CPU、内存、文件系统、存储系统、内容分布、数据库等等,都会遵循这样的策略。比如:
- 程序设计中,对于可能重复创建和销毁,且创建销毁代价很大的对象(比如套接字和线程),也可以缓存,对应的缓存形式,就是连接池和线程池等。
- 对于消耗较大的计算,也可以将计算结果缓存起来,下次可以直接读取结果。比如对递归代码的一个有效优化手段,就是缓存中间结果。
在有IO(比如网络IO和磁盘IO)的时候,合并操作和批量操作往往能够提升吞吐量,提高性能。
- 批量IO读写:就是在有多次IO的时候,可以把它们合并成一次读写数据。这样可以减少读写时间和协议负担
- 数据库的读写操作,也可以尽量合并。比如键值数据库的查询,最好一次查询多个键,而不要分成多次。
- 网络请求时,网络传输的时间可能远远大于请求的处理时间,因此合并网络请求也很有必要。上次协议的端对端对话次数尽量不要太频繁,否则,总的应用层吞吐量不会很高
这两个策略是紧密配合的,比如先进的算法有时候会需要先进的数据结构;而且它们往往和程序的设计代码直接相关

同一个问题,肯定会有不同的算法实现,进而就会有不同的性能
对每一种具体的场景(包括输入集合大小、时间空间的要求、数据的大小分布等),总会有一种算法是最适合的。我们需要考虑实际情况,来选择这一最优的算法。
没有一个数据结构是在所有情况下都是最好的。我们要权衡取舍,找出实际场合下最适合的高效的数据结构。



